

近日,Interspeech 2024会议发出了审稿结果通知,语音及语言信息处理国家工程研究中心智能语音信息处理团队共17篇论文被会议接收,论文方向涵盖语音识别、语音合成、语音编码、话者识别、语音增强、情感识别、声音事件检测等,各接收论文简介见后文。
Interspeech是由国际语音通信协会(ISCA)组织的语音研究领域的顶级会议之一,是全球最大的综合性语音信号处理领域的科技盛会。本届会议以“Speech and Beyond”为主题,内容涵盖语音识别、语音合成、语音编码、语音增强、自然语言处理等多个领域。
语音及语言信息处理国家工程实验室于2011年由国家发展改革委正式批准成立,由中国科学技术大学和科大讯飞股份有限公司联合共建,是我国语音产业界的国家级研究开发平台。2021年底,实验室通过国家发展改革委的优化整合评估,成功纳入新序列,并转建为语音及语言信息处理国家工程中心。
1. A Low-Bitrate Neural Audio Codec Framework with Bandwidth Reduction and Recovery for High-Sampling-Rate Waveforms
论文作者:艾杨,鲁叶欣,江晓航,盛峥彦,郑瑞晨,凌震华
论文单位:中国科学技术大学
论文简介:

本文提出了一种结合频带削减和恢复的神经网络音频编解码框架,应用在高采样率和低比特率的音频压缩场景中。提出的框架由一个基于两阶段下采样的编码器、一个量化器和一个基于两阶段上采样的解码器组成。编码器在编码波形之前初步对高采样率波形进行频带削减。因此,量化器输出的离散表征来自于低采样率波形,比特率较低。解码器解码出低采样率波形,并通过频带恢复还原高采样率波形。客观和主观实验均证实,我们提出的编解码框架能够在48kHz采样率和仅1kbps比特率下实现高质量音频编码,相比于一些没有结合频带削减和恢复的基线音频编解码器,比特率节省了大约6倍。
论文资源:Demo语音网页 https://yangai520.github.io/APCodec_APBWE
2. Multi-Stage Speech Bandwidth Extension with Flexible Sampling Rate Control
论文作者:鲁叶欣,艾杨,盛峥彦,凌震华
论文单位:中国科学技术大学
论文简介:
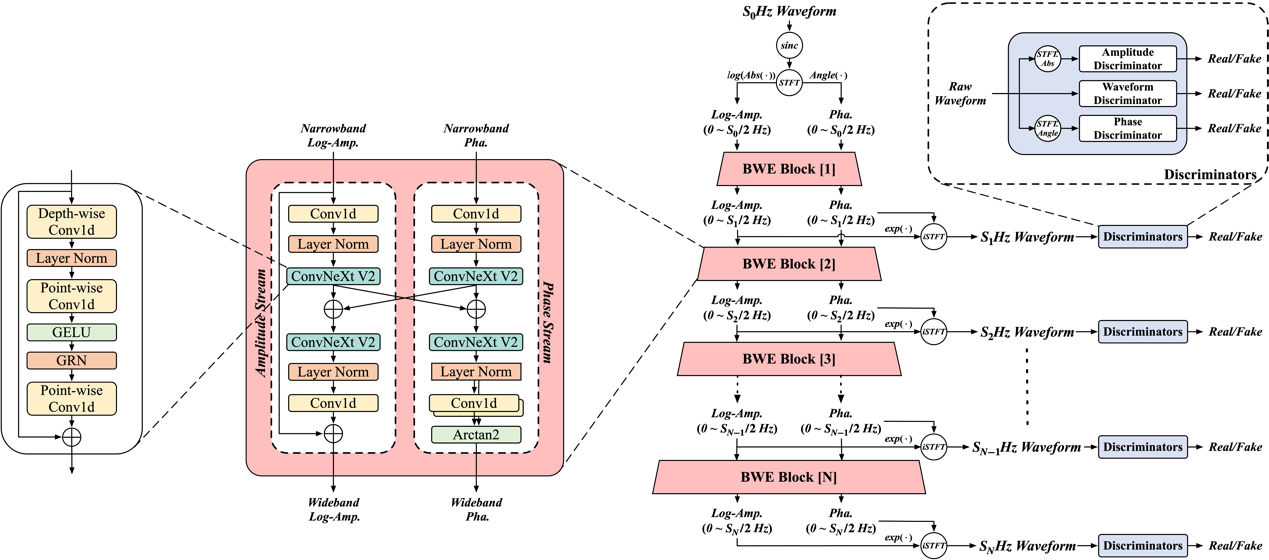
语音频带扩展(Bandwidth Extension, BWE)旨在扩展语音信号的频带范围,增强语音的质量以及可懂度。如今绝大多数的语音频带扩展模型都在固定的源和目标采样率的限制下运行,因而限制了它们在实际应用场景中的灵活性。因此,我们提出了一种多阶段的语音频带扩展模型 MS-BWE,它能够处理一系列源-目标采样率对,从而实现频带之间的灵活扩展。所提出的 MS-BWE 模型包括一系列级联的 BWE 模块,每个模块采用双流架构来分别实现幅度和相位扩展,逐阶段扩展语音频带。为了缩小训练和推理过程之间的差异,MS-BWE 在训练时采用了 teacher-forcing 的策略,随机采样真实的或者生成的幅度相位谱作为 BWE 块的输入。实验结果表明,我们提出的 MS-BWE 在语音质量上与 SOTA 的语音频带扩展方法相当。在生成效率方面,MS-BWE 的单阶段生成在 GPU 上可以实现超过一千倍的实时速度,在 CPU 上也达到约为六十倍的实时速度。
论文资源:Demo语音网页https://yxlu-0102.github.io/MS-BWE-demo
3. BiVocoder: A Bidirectional Neural Vocoder Integrating Feature Extractionand Waveform Generation
论文作者:杜荟鹏,鲁叶欣,艾杨,凌震华
论文单位:中国科学技术大学
论文简介:
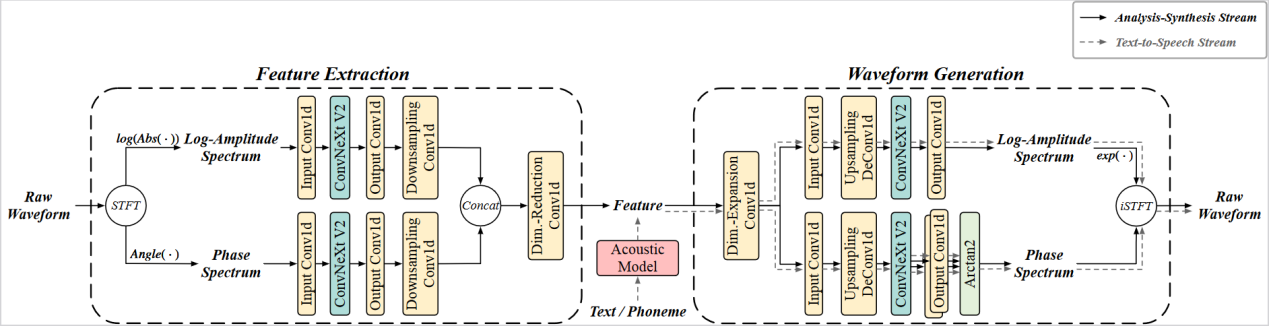
本文提出了一种新颖的双向神经网络声码器,名为BiVocoder,能够在短时傅里叶变换(STFT)域内进行特征提取和波形生成。对于特征提取,BiVocoder将从短时傅里叶变换提取的幅度和相位谱作为输入,通过卷积神经网络将它们转换为长帧移和低维特征。由此提取的特征适用于声学模型的直接预测,支持其在文本转语音(TTS)任务中的应用。对于波形生成,BiVocoder通过对称网络从特征中恢复幅度和相位谱,然后进行逆短时傅里叶变换以重构语音波形。实验结果表明,我们提出的BiVocoder在综合考虑合成语音质量和推断速度方面,比一些基线声码器表现更好。
论文资源:Demo语音网页https://redmist328.github.io/BiVcoder_demo
4. Refining Self-Supervised Learnt Speech Representation using Brain Activations
论文作者:李恒宇,梅康迪,刘朝辞,艾杨,陈丽萍,张结,凌震华
论文单位:中国科学技术大学
论文简介:
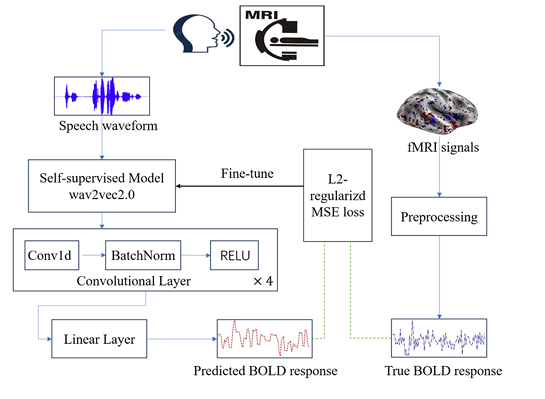
先前有研究表明自监督预训练模型提取的语音表征与人类大脑对语音的感知表现出相似性,利用下游任务微调语音表征模型可以进一步提高相似性。然而,这种相似性是否可以用于优化预训练的语音模型仍不清楚。因此,在本文的工作中,我们使用fMRI记录的人脑激活信号,通过将模型表征与人类神经反应对齐,将人脑对语音的神经感知编码到模型的参数中来完善常用的wav2vec2.0模型。在语音处理通用性能基准(SUPERB,Speech processing Universal PERformance Benchmark)上的实验结果表明,这种操作有利于后续的下游任务,如说话人验证、自动语音识别、意图分类。然后,可以将所提出的方法视为改进自监督语音模型的新替代方案。
5. Asynchronous Voice Anonymization Using Adversarial Perturbation On Speaker Embedding
论文作者:王瑞,陈丽萍,Kong Aik Lee,凌震华
论文单位:中国科学技术大学,香港理工大学
论文简介:
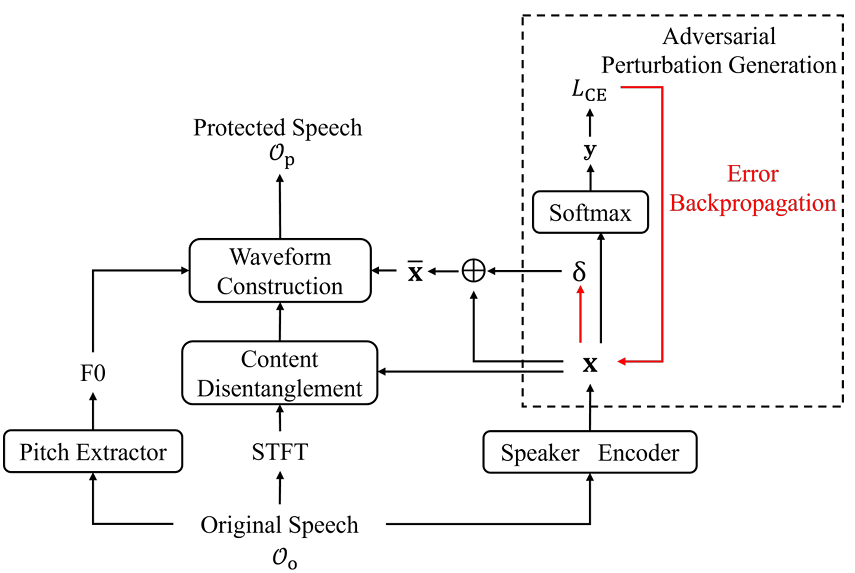
语音匿名化(Voice Anonymization)作为一种隐私保护技术,通过将原语音中的说话人替换为伪说话人,达到保护原说话人隐私信息的目的。该方法在保护原说话人信息不被机器感知的同时,也改变其主观听感,无法同时满足既能保护说话人信息不被机器算法正确感知,又能保留说话人主观听感的场景需求。为此,本文提出异步语音匿名化(Asynchronous Voice Anonymization)任务,并在基于说话人信息解耦框架的语音生成模型之上,提出基于说话人表征对抗扰动的异步匿名化语音生成方法。具体地,对从原语音中提取的说话人表征,本文采用FGSM方法生成其对抗扰动,并根据扰动后的说话人表征生成匿名化语音。本研究实验采用YourTTS为语音生成模型,在LibriSpeech数据集上展开,在测试集共1522句语音中,60.71%的生成语音保留了原话者的主观听感,同时说话人确认实验结果表明,相比于原说话人信息,以上语音中的说话人信息的机器感知被改变,证明了本文所提方法的有效性,同时展示了异步语音匿名化任务的可实现性。
论文资源:Demo语音网页https://voiceprivacy.github.io/asynchronous-voice-anonymization/
6. Clever Hans Effect Found in Automatic Detection of Alzheimer's Disease through Speech
论文作者:刘寅龙,冯锐,袁家宏,凌震华
论文单位:中国科学技术大学
论文简介:
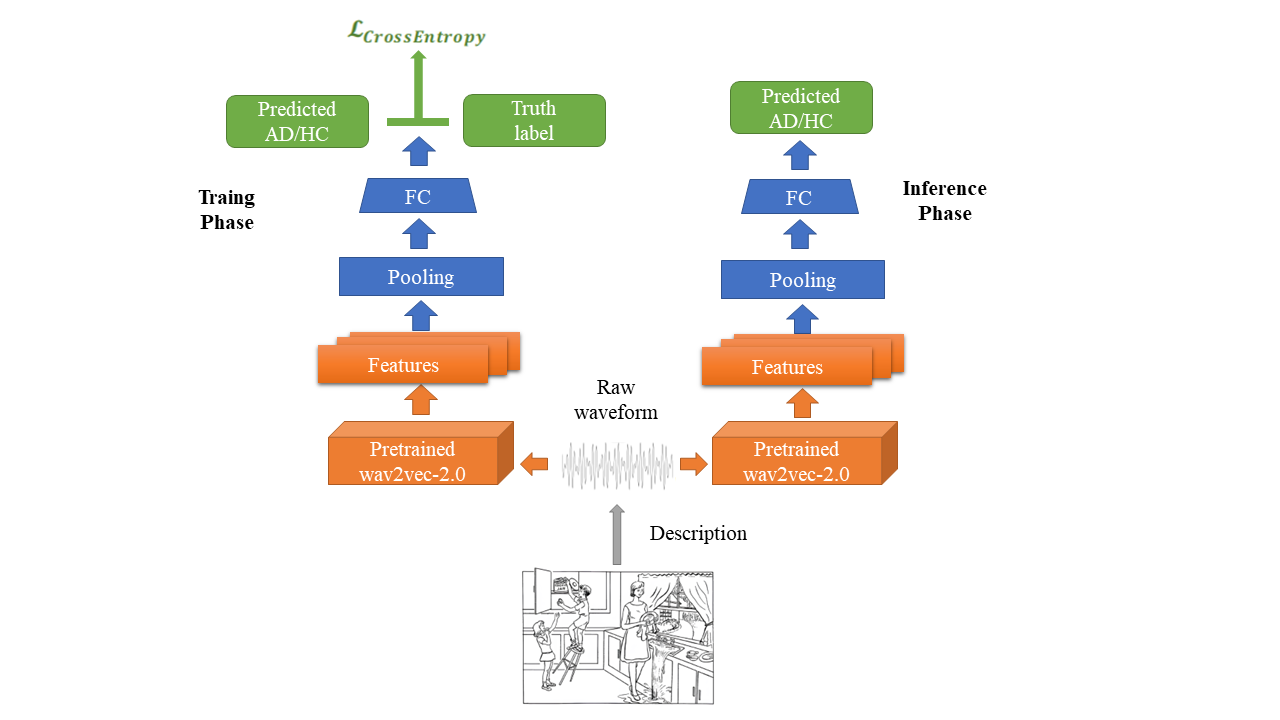
本文揭示了目前最大的公开可访问的用于阿尔茨海默病(AD)检测研究的Pitt语料库中的图片描述任务的音频录音中存在的一种潜在偏差。即使仅利用这些音频录音的静音片段,我们也能实现近乎100%的AD检测准确率。然而,将相同的方法应用于其他数据集和预处理过的Pitt录音,AD检测的准确率则恢复到常规水平(约80%)。这些结果表明,在Pitt语料库上的AD检测存在“聪明的汉斯效应”。我们的研究结果强调了对用于训练深度学习模型的数据集中存在的固有偏差保持警惕是非常重要的,并突出了更好地理解模型性能的必要性。
7. MAT-SED: AMasked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
论文作者:蔡鹏飞、宋彦、李康、宋皓宇、Ian McLoughlin
论文单位:中国科学技术大学、澳大利亚国立大学、新加坡理工大学
论文简介:
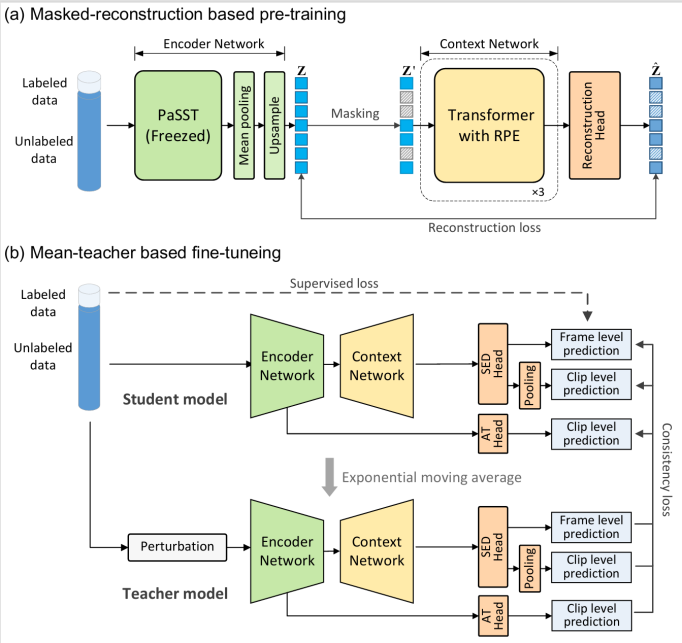
在近期的DCASE竞赛中,利用预训练Transformer编码器的声音事件检测方法展现了优异的性能。然而,受限于标注数据的匮乏,现有方法在建模声音事件的时间依赖性时,仍需依赖基于RNN的结构。在本研究中,我们提出了一种完全基于Transformer的声音事件检测模型MAT-SED。MAT-SED使用基于掩码重建的任务进行预训练。具体来说,我们采用使用相对位置编码的Transformer架构代替传统的RNN结构,构成上下文网络,并通过自监督的掩码重建任务进行预训练。之后,编码器和上下文网络以半监督的方式进行联合微调。此外,我们还使用了一种全局-局部特征融合策略,以增强模型对声音事件的定位能力。在DCASE2023任务4的评估中,MAT-SED取得了0.587/0.896的PSDS1/PSDS2,超过了当前最先进的声音事件检测系统。
8. An Effective Local Prototypical Mapping Network for Speech Emotion Recognition
论文作者:奚宇轩、宋彦、戴礼荣、宋皓宇、Ian McLoughlin
论文单位:中国科学技术大学、澳大利亚国立大学、新加坡理工大学
论文简介:
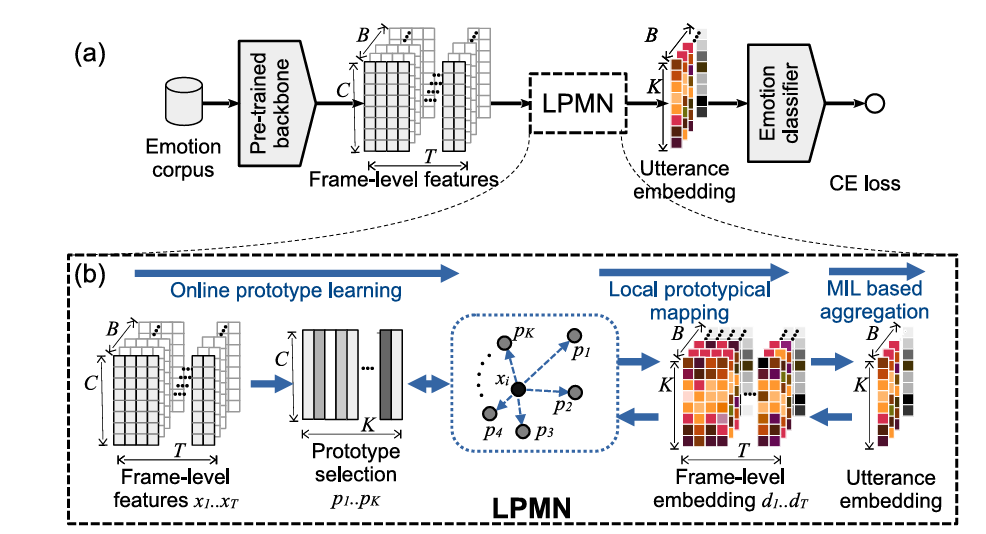
现有语音情感识别系统通常使用段级的情感标注进行优化。但情感作为一种复杂的心理学现象,其表达往往不局限于单一的、静态的段级标签。本文提出了一种局部原型映射网络(local prototypical mapping network,LPMN)来对帧级情感方差进行建模,更好地利用一句话中局部信息的差异来提高性能。具体而言,我们首先构建一个原型集合,用以表征从预训练的特征提取器得到的复杂帧级特征。接着基于多实例学习算法,通过特征和原型之间的相似性度量来选择最能代表情感的映射,从而获得段级嵌入,进行情感分类。原型可以使用量化损失和情感分类损失进行联合优化。最后,我们在后处理阶段进一步提出了一种原型选择方案,选择与情感相关的原型,以减少不相关因素造成的干扰。我们在IEMOCAP和MER2023数据集上进行了实验,证明了LPMN的有效性。
9. DB-PMAE: Dual-Branch Prototypical Masked AutoEncoder with locality for domain robust speaker verification
论文作者:谢玮琳、奚宇轩、宋彦、张建涛、宋皓宇、Ian McLoughlin
论文单位:中国科学技术大学、澳大利亚国立大学、新加坡理工大学
论文简介:
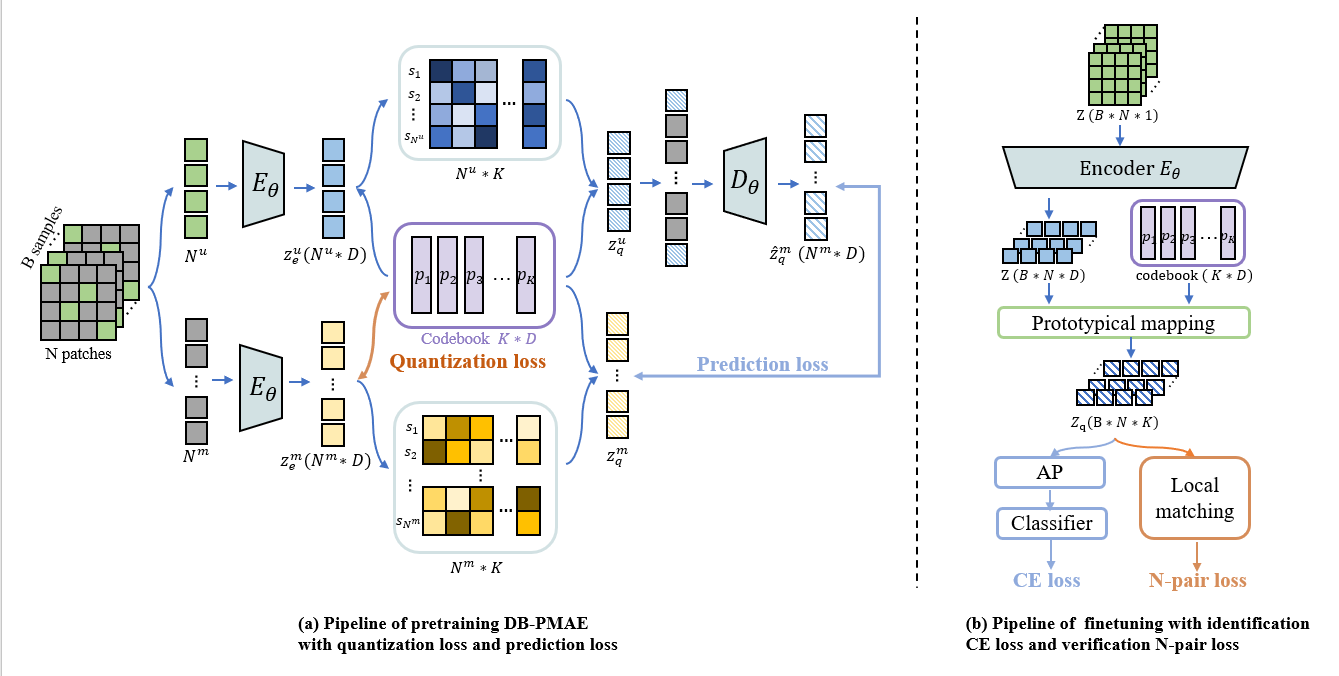
现有的说话人验证(SV)系统主要由深度嵌入网络预训练的说话人识别(SID) 前端和提供相似性度量的微调网络后端组成。尽管它们取得了成功,但由于领域不匹配问题,现有系统的性能可能会显著降低。在本文中,我们提出了一种新的基于双支路原型掩码自编码器(Dual-Branch Prototypical Masked AutoEncoder,DB-PMAE)的SRE框架。具体来说,我们对于带有孪生编码器的教师和学生分支进行预训练,共同学习patch级别的特征和原型。我们利用多任务学习框架对SID和SV任务进行微调,其中通过寻找局部对应来度量相似性,以提高域鲁棒性。我们在CNCeleb语料库上的实验结果证明了DB-PMAE的优越性。
10. Adapter Learning from Pre-trained Model for Robust Spoof Speech Detection
论文作者:吴皓晨,郭武,彭圣宇,李珠海,张结
论文单位:中国科学技术大学
论文简介:
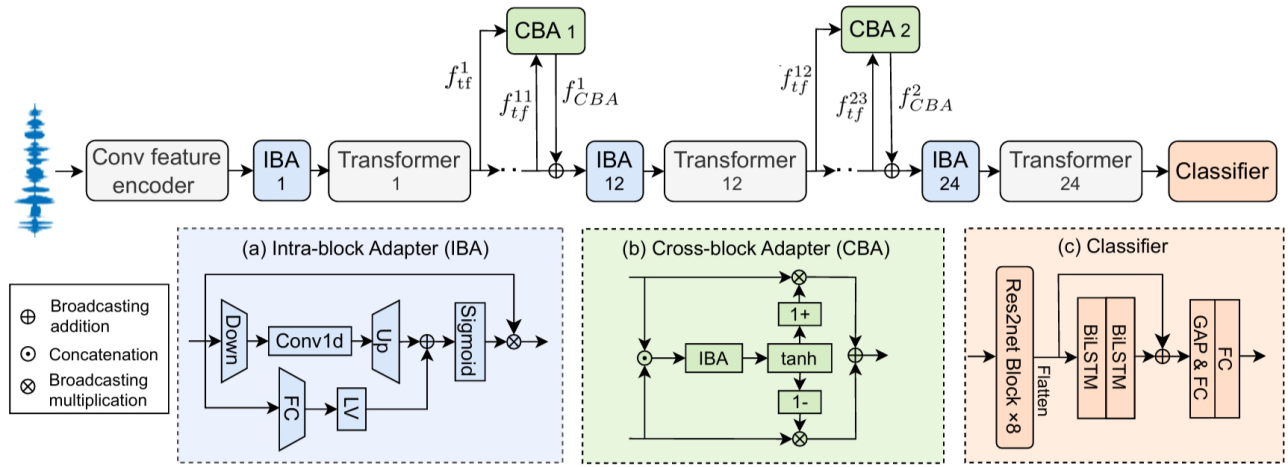
伪造语音检测模型可以通过使用大规模预训练模型(如 Wav2vec2 或 WavLM)作为前端来提升模型的泛化能力。然而,由于训练数据有限,对预训练模型进行微调除了计算量大之外,还容易出现过拟合和灾难性遗忘的问题。在本文中,我们提出了一种基于预训练模型的新型适配器学习框架,用于稳健的伪造语音检测。我们考虑了两种适配器情况,即添加到wav2vec2主干网络的块内适配器和跨块适配器。训练过程中冻结wav2vec2主干网络,仅更新适配器的参数。通过提出的适配器学习方法,只需增加少量参数,就能有效学习用于伪造语音检测的任务相关信息。在三个基准数据集上的结果验证了该系统优于基线系统和现有的SOTA系统。
11. Spoofing Speech Detection by Modeling Local Spectro-Temporal and Long-term Dependency
论文作者:吴皓晨,郭武,张震涛,赵文婷,彭圣宇,张结
论文单位:中国科学技术大学,中国招商银行
论文简介:
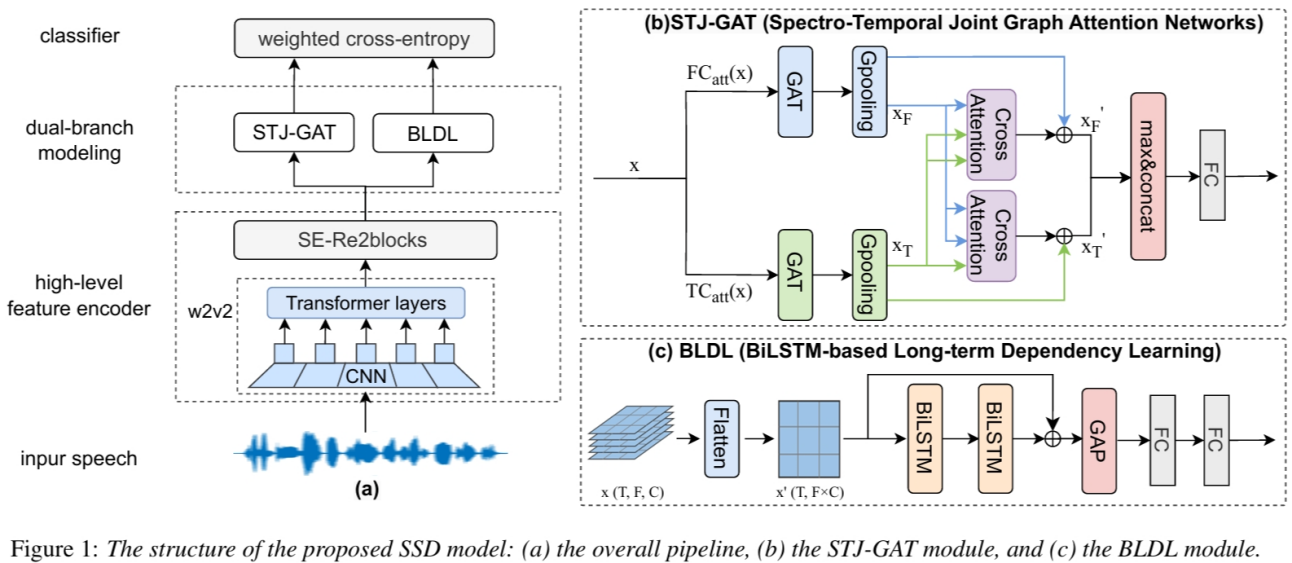
本研究提出了一种双分支网络,利用语音的局部和全局信息进行伪造语音检测(SSD)。伪造语音的局部人工伪影可能存在于特定的时间或频谱区域,而这正是SSD系统的主要目标。因此,我们提出了一种频率-时间图注意力网络,以联合捕捉伪造语音的时间和频谱差异信息。与现有方法不同的是,所提出的方法利用交叉注意机制来交互建模频谱-时间依赖性。由于全局伪影也能为SSD提供补充信息,我们使用了基于BiLSTM的分支来建模长时的区分性信息。然后,利用加权交叉熵损失对这两个分支分别进行优化,并以相等的权重融合得分。在三个基准数据集(即 ASVspoof 2019、2021 LA 和 2021 DF)上的结果表明,所提出的方法优于先进的系统。
12. Enhancing Voice Wake-Up for Dysarthria: Mandarin Dysarthria Speech Corpus Release and Customized System Design
论文作者:高铭,陈航,杜俊,徐昕,郭泓霄,卜辉,杨建兴,李明,李锦辉
论文单位:中国科学技术大学,希尔贝壳,北京理工大学,昆山杜克大学,佐治亚理工学院
论文简介:
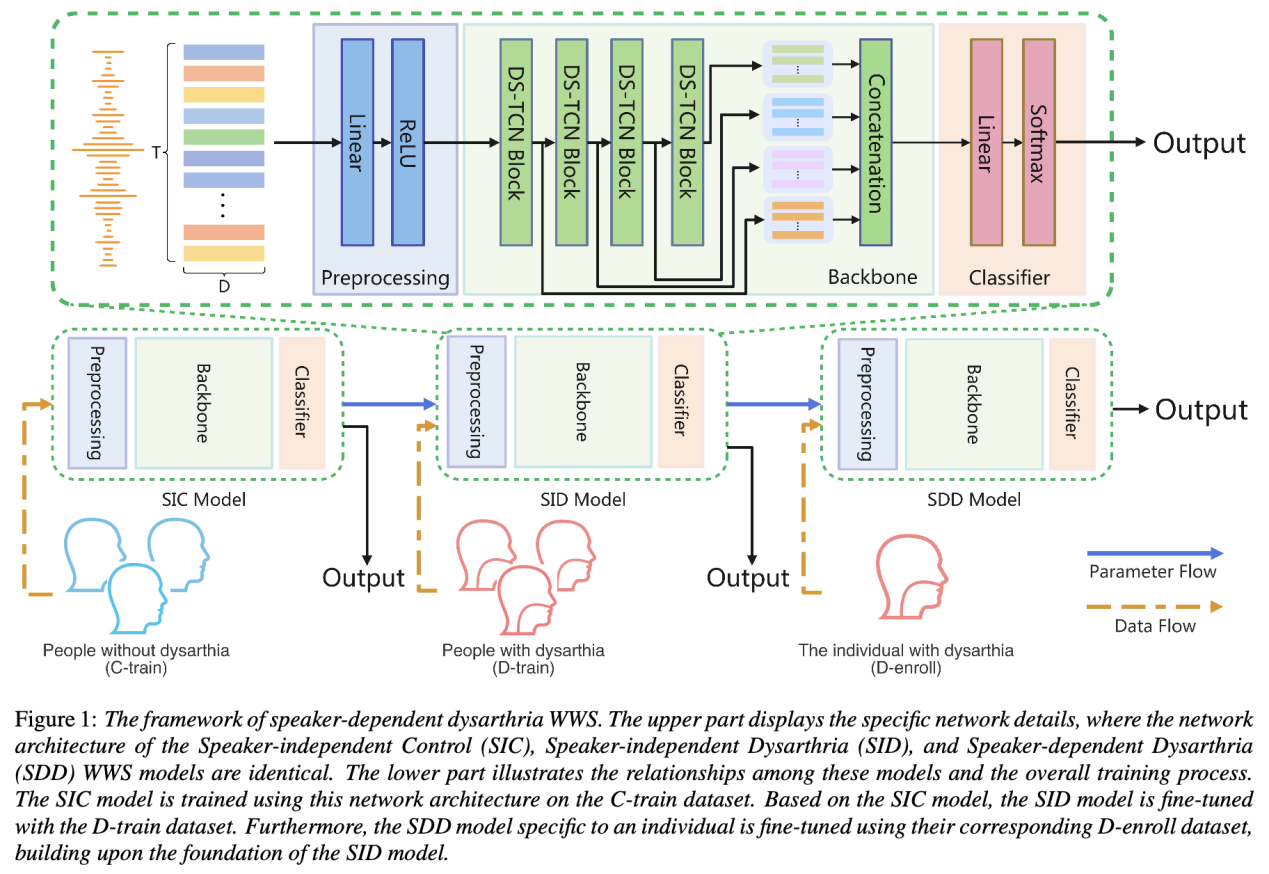
本文发布了一个中文普通话构音障碍语音数据集(MDSC)并开发了一个定制的语音唤醒系统。MDSC是一个专为家居场景中的构音障碍者设计的开源语音数据集,包含年龄、性别、疾病类型和可懂度评估等信息。本文通过对该语音数据集的全面实验分析,展示了在处理构音障碍语音时遇到的挑战,并提出了一种在性能上表现优异的特定人构音障碍语音唤醒系统。该系统针对构音障碍者的特殊需求进行了优化,显著提升了语音唤醒技术的适应性和包容性,进一步推动这一领域的研究和应用。
论文资源:数据集地址:https://www.aishelltech.com/aishell_6(即将开源)
代码地址:https://github.com/greeeenmouth/LRDWWS
13. Lightweight Transducer Based on Frame-Level Criterion
论文作者:万根顺,王孟之,茆廷志,陈航,叶中付
论文单位:中国科学技术大学,科大讯飞
论文简介:
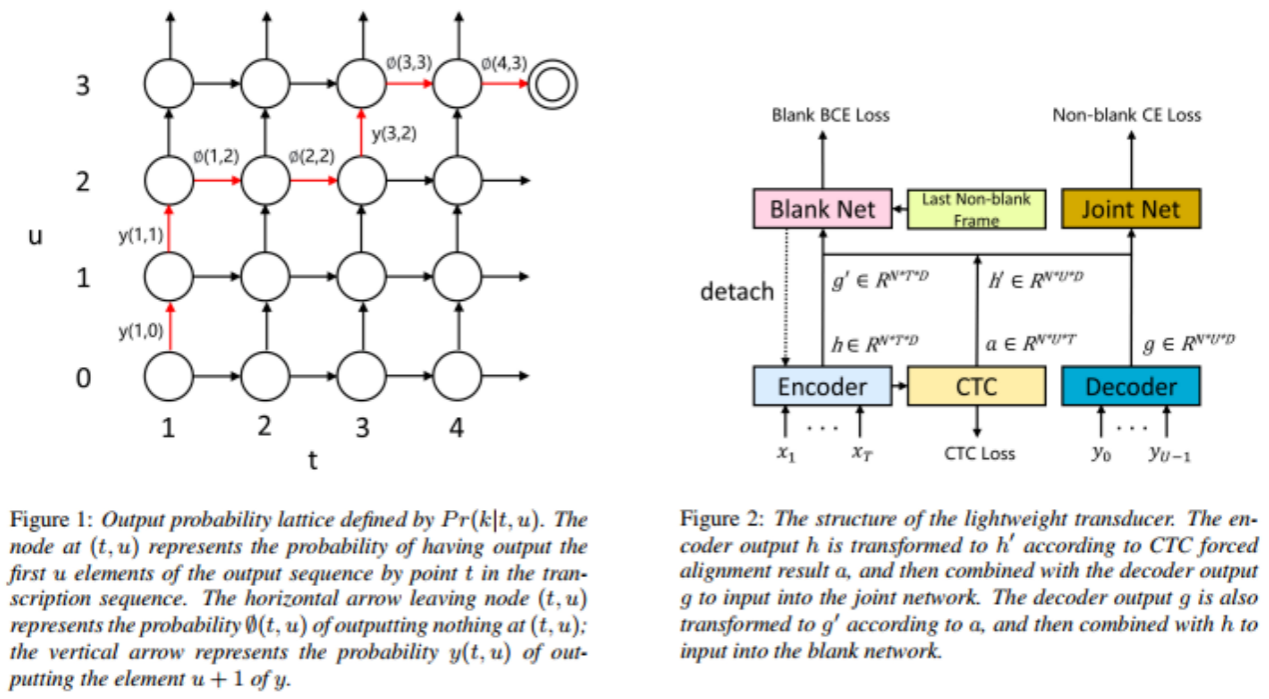
如图1所示,传统的基于序列级对其准则训练的Transducer模型由于需要生成较大的概率矩阵,需要占用较大的内存。本文提出了一种基于帧级对齐准则的轻量级Transducer模型,如图2所示,利用 CTC 强制对齐算法的结果确定每一帧的标签,然后将编码器输出与解码器输出的相应时刻的输出进行合并,而不需要像传统模型那样将编码器输出的每个元素与解码器输出的每个元素相加,从而大大降低内存和计算量。针对标签空白过多导致分类不平衡的问题,我们将空白和非空白概率解耦,并将空白分类器的梯度截断到主网络,使得轻量级Transducer能够达到与传统Transducer相近的效果,同时利用更丰富的信息来预测空白概率,从而取得优于传统Transducer的效果。
14. LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance
论文作者:陈世豪,顾宇,张结,李娜,陈日林,陈丽萍,戴礼荣
论文单位:中国科学技术大学,腾讯
论文简介:
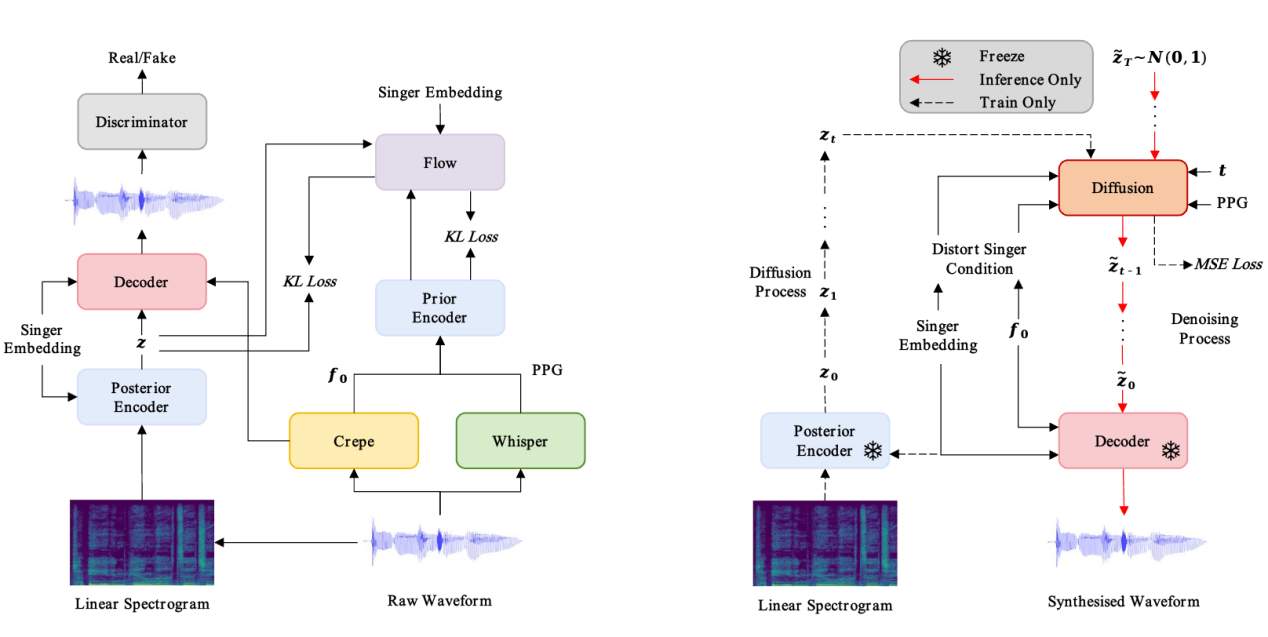
任何人到任何人(Any-to-Any)的歌声转换 (Singing Voice Conversio) (SVC) 是一种目前热门的音频编辑技术,旨在仅需几秒钟的歌唱数据的条件下,将一个歌手的歌声转换为另一个歌手的歌声。然而,在转换过程中,音色泄漏问题是不可避免的:转换后的歌声仍然听起来像原歌手的声音。为了解决这个问题,我们在本文中提出了一种基于潜扩散模型的SVC框架 (LDM-SVC),该模型使用 LDM 在潜在空间中进行 SVC任务,因此我们预训练了一个基于 VITS 框架的变分自编码器(VAE)结构,使用的是被广泛应用的开源 So-VITS-SVC 项目,然后使用预训练的VAE用于 LDM 的训练。此外,我们提出了一种基于Classifier-Free Guidance方法的音色引导训练方法,以进一步抑制原歌手的音色。实验结果表明,转换后的音频也有着较高的流畅度,并且该方法在音色相似性的主观和客观评估中均优于以往的工作。
15. Fine-tune Pre-Trained Models with Multi-Level Feature Fusion for Speaker Verification
论文作者:彭圣宇,郭武,吴皓晨,李作亮,张结
论文单位:中国科学技术大学
论文简介:
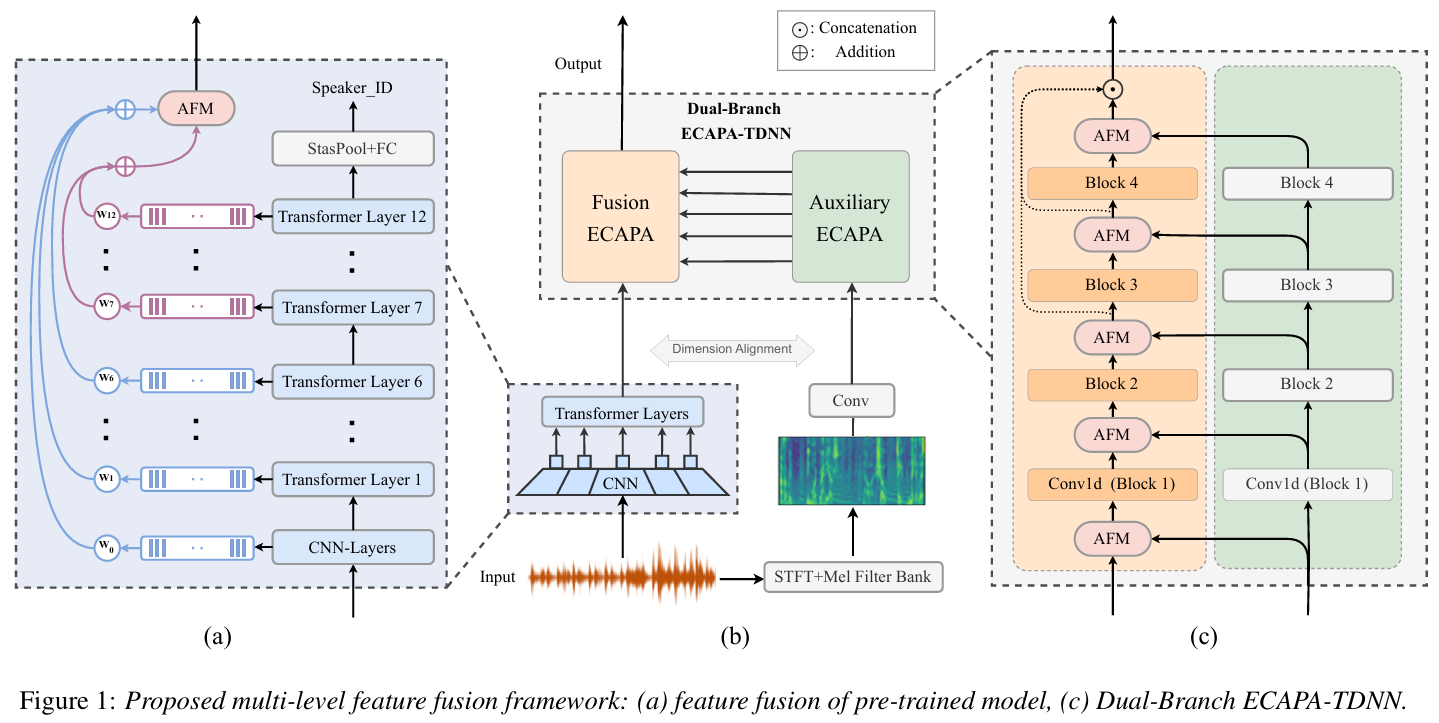
本文使用多层次特征来微调预训练模型进行说话人验证任务,多层次特征包括来自预训练模型的特征和传统手工特征。本文所提出的框架包含一个预训练模型作为前端和一个双分支ECAPA-TDNN (DBE) 后端。对于前端,我们提出了一个基于注意的融合模块 (AFM) 来合并预训练模型的深层特征和浅层特征。为了提高性能,我们在预训练模型的最后一层之后添加了辅助说话人损失。对于DBE后端,DBE的每个分支都采用来自预训练模型和FBank特征的融合后特征作为输入。AFM进一步用于合并双分支特征以提供互补信息。VoxCeleb数据集上的实验结果证实了我们提出的方法在不同预训练模型上的有效性。
16. Contrastive Learning and Inter-Speaker Distribution Alignment Based Unsupervised Domain Adaptation for Robust Speaker Verification
论文作者:李作亮,郭武,古斌,彭圣宇,张结
论文单位:中国科学技术大学
论文简介:
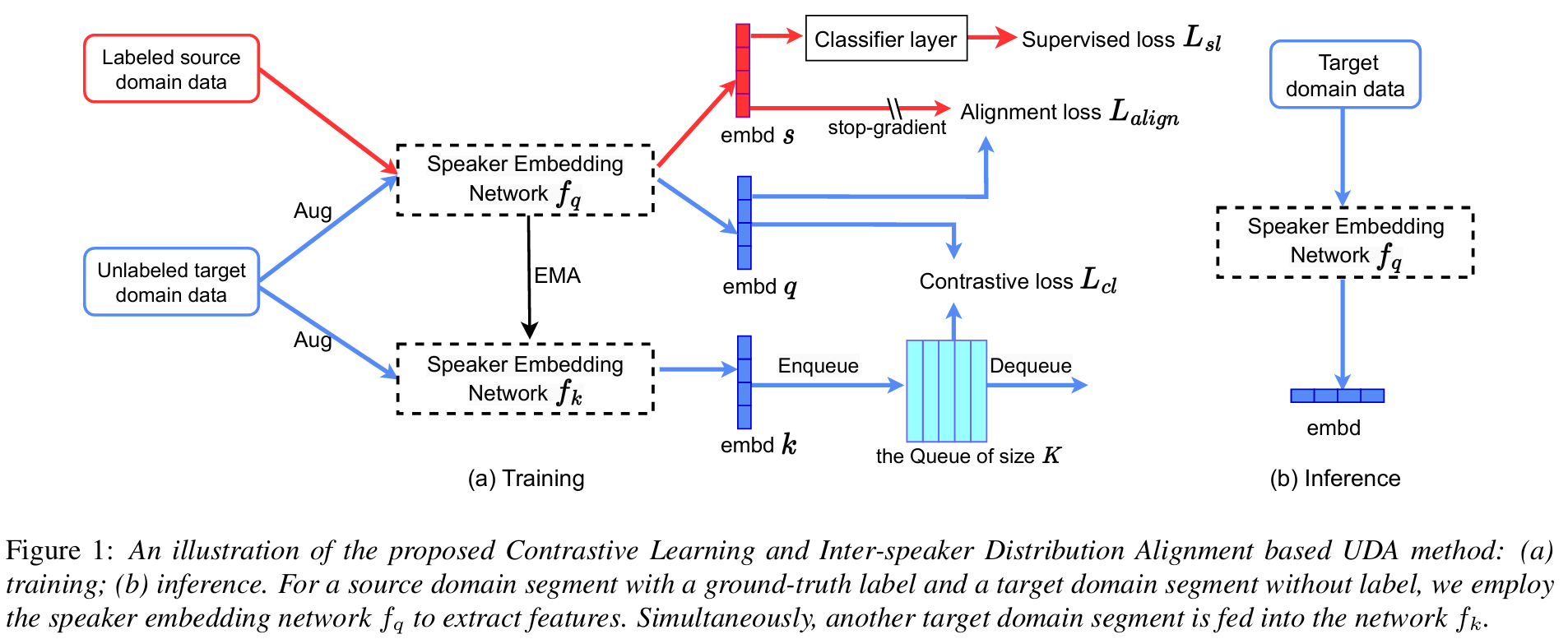
无监督域自适应 (Unsupervised Domain Adaptation,UDA) 可以解决说话人确认在实际应用中源域和目标域之间的不匹配问题。在本文中,我们提出了一种UDA方法,通过自监督方法利用目标域数据。首先,我们使用动量对比学习来有效利用目标域中的潜在说话人标签,同时增强说话人内部的紧凑性和说话人之间的可分离性。其次,我们改进了说话人之间的特征分布对齐损失,确保源域统计量的稳定性并减轻目标域假负对的影响。这两种方法进一步与源域中的传统监督学习相结合。以Voxceleb2作为源域, CN-Celeb1作为目标域的实验结果证明了我们提出的方法的有效性。
17. Boosting the Transferability of Adversarial Examples with Gradient-Aligned Ensemble Attack for Speaker Recognition
论文作者:李珠海,张结,郭武,吴皓晨
论文单位:中国科学技术大学
论文简介:
在针对说话人识别系统的黑盒攻击中,如果对抗样本能够一致地欺骗替代模型的集合,他们就能针对未知的受害者系统表现出更好的可迁移性。在这项工作中,我们提出了一种梯度对齐的集成攻击(Gradient-Aligned Ensemble Attack,GAEA)方法,该方法找到一组替代模型的最优梯度方向,以更新对抗样本。具体来说,我们首先通过随机掩蔽输入声学特征的部分区域来计算每个替代模型的过拟合缓和梯度。然后,我们根据每个替代模型的梯度与其他模型梯度的一致性,得到每个替代模型的梯度权重。最终的更新梯度由所有替代模型的梯度加权和计算得出。在VoxCeleb数据集上的实验结果验证了所提出的方法在说话人辨认和说话人确认任务中的有效性。